One of the most significant concepts in data structures and computer science is trees. They offer a hierarchical method of organizing data and hence it becomes easier to store, manage, search and retrieve information easily. Trees, unlike linear data structures like arrays and linked lists, are a representation of relationships between objects in a parent-child format. This special architecture contributes to their suitability to solve complex computational problems and handle large datasets.
Trees are common in databases, file systems, search engines, artificial intelligence, and networking applications in modern software development. The knowledge of tree operations is critical to programmers, software engineers, and anyone who may be interested in data structures and algorithms.
What Is a Tree in Data Structures?
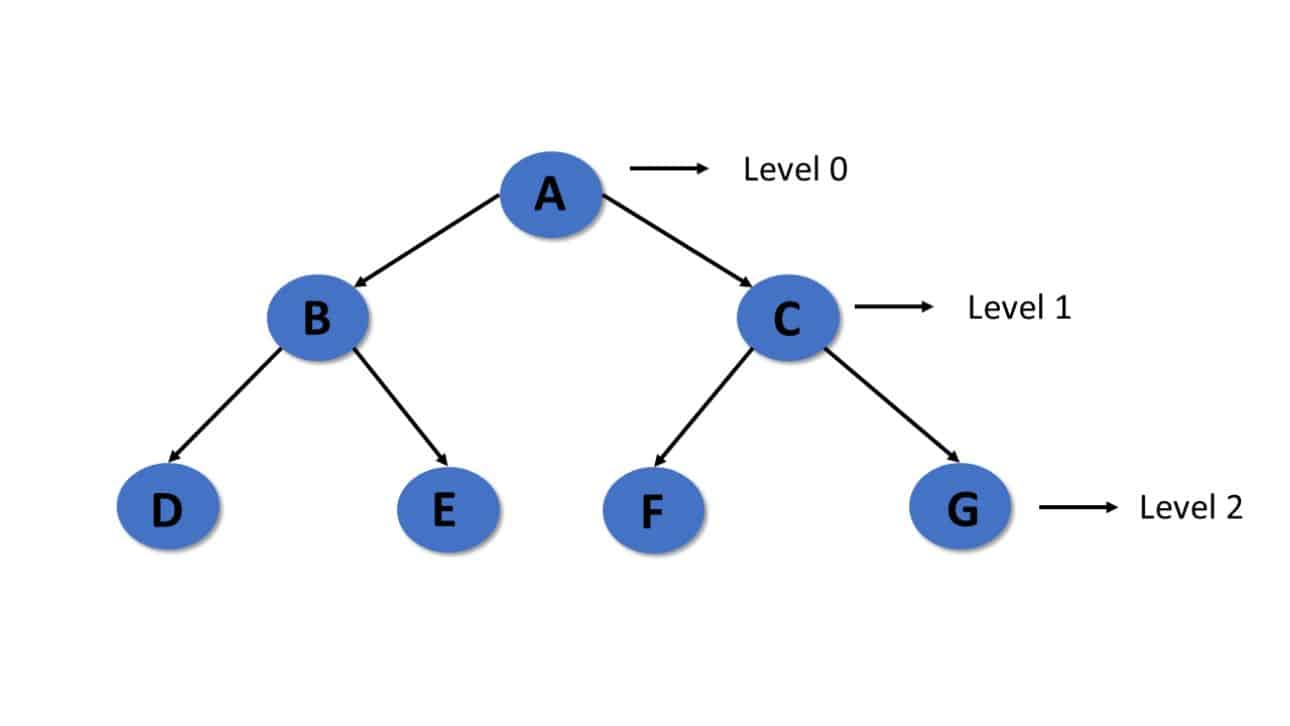
A tree care is a non-linear data structure where the data is represented by nodes and the edges between the nodes. The highest node is referred to as the root node and all the other nodes are interrelated by parent-child relationships. A node may have none or more child nodes, forming a branching structure, which looks like an upside-down tree.
The following are some of the key terms related to trees:
Root Node: The first node of the tree.
Parent Node: This is a node that has child nodes.
Child Node: A node that is descended by some other node.
Leaf Node: A node that has no children.
Edge: An edge between two nodes.
Height: The greatest depth of the tree.
Subtree: A smaller tree that is a child of a node and its children.
Such a hierarchical structure enables the data to be arranged effectively and accessed fast.
Key Characteristics of Tree Data Structures
There are a number of distinctive features of trees that render them useful in computer science.
First, they are hierarchical relationships in nature. As an example, a tree can be easily used to model a company structure, folder system or family tree.
Second, trees offer effective searching and sorting. A lot of tree-based algorithms are much faster than linear structures when large data sets are involved.
Third, trees support dynamic data management. It is possible to insert, delete, or edit nodes without restructuring the whole structure.
Another important characteristic is scalability. Trees are scalable to grow with data and they have efficient performance. This makes them suitable for applications that handle millions of records or user interactions.
Due to these advantages, trees are regarded as one of the basic building blocks of algorithm design and software development.
Types of Trees in Data Structures
Trees can be of various types and each has its purpose and use.
Binary Tree
A binary tree is a tree in which each node can have at most two children, commonly referred to as the left child and right child. The use of binary trees is popular due to its simplicity and efficiency.
Binary Search Tree (BST)
Binary Search Tree has a particular rule: the values which are less than the parent node are on the left, and the ones which are greater are on the right. This structure enables quick search, insertion and deletion.
AVL Tree
AVL tree is a self-balancing Binary Search Tree. It is self-balancing following deletions and insertions and thus has consistent performance.
B-Tree
B-Trees are commonly used in databases and file systems. They are created to manage huge volumes of data in disks effectively.
Heap Tree
A heap is a special tree that is utilized in priority operations. It is usually used in priority queues and scheduling systems.
Trie
A prefix tree or Trie is an efficient storage and search method of storing strings. It is commonly employed in autocomplete applications, spell checkers and dictionaries.
The tree types are used in various applications and have their own benefits based on the usage.
Tree Traversal Techniques
The systematic visit to all the nodes in a tree is known as tree traversal. Tree data searching, processing, and display require traversal.
The most prevalent traversal techniques are:
Preorder Traversal
In this approach, the root node is traversed initially, then the left subtree and finally the right subtree.
Inorder Traversal
The left subtree is visited, and then the root node and the right subtree. This traversal generates sorted output in Binary Search Trees.
Postorder Traversal
The traversal goes to the left subtree, then the right subtree and finally the root node.
Level Order Traversal
The nodes are traversed at each level (top to bottom). Queues are usually used to implement this method.
These traversal methods are basic to carry out different operations on tree-like structures.
Advantages of Using Trees
The benefits of trees are many and this makes them a favorite in most computing applications.
Efficient data retrieval is one of the key benefits. Balanced trees are capable of search operations that are much faster than linear structures.
Trees are also very good at representing hierarchical data. Complex relationships are modeled in a clear and logical way.
Dynamic memory utilization is another advantage. Trees are able to grow and shrink on demand without having to allocate adjacent memory.
Also, trees enhance sorting and indexing. A lot of database systems are based on tree structures to speed up query execution and access of data.
Trees are a critical part of the sophisticated software systems and algorithms due to their flexibility and efficiency.
Real-World Applications of Trees
Tree data structure is widely utilized in real-world technology and software systems.
File management systems arrange folders and files in a tree structure. Each directory may have many subdirectories and files, which create a tree structure by default.
B-Trees and similar structures are used as database management systems to index records and search through them efficiently. This enables databases to execute queries in a short time even when dealing with huge datasets.
Tree-based algorithms used by search engines to index web pages and provide relevant search results are efficient.
Routing protocols in computer networks are frequently tree-based, and they are used to find the best communication routes between devices.
Decision trees are also used in artificial intelligence and machine learning to classify, predict, and make decisions.
Moreover, syntax trees are used by compilers to process programming languages and translate the source code into instructions that can be executed by a machine.

